Code-Level Insight at 2AM
Code-Level Insight at 2AM
My throat went desert-dry when Slack exploded at 2:17AM. Not the usual overnight ping, but 47 unread messages screaming about payment processing failures during Black Friday prep. I scrambled to my home office in boxers, laptop already humming with panic. Five different monitoring tools stared back at me - fragmented chaos of server metrics, APM traces, and cloud logs. None connected the dots between spiking Kubernetes errors and our dying PostgreSQL cluster. My fingers trembled over the keyboard until I remembered the crimson icon on my phone: ManageEngine Applications Manager.
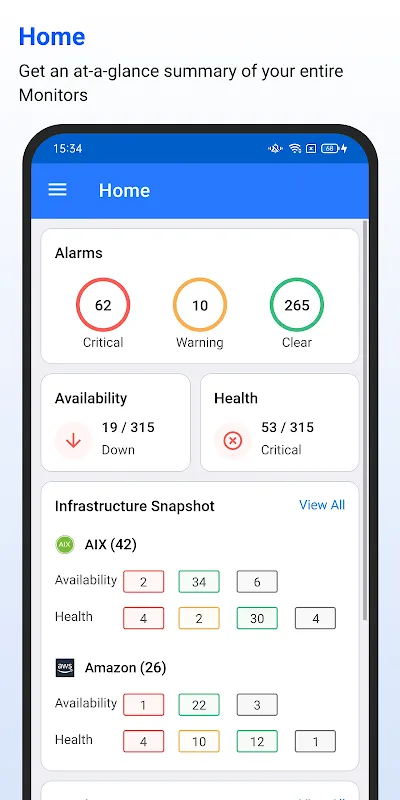
That initial skepticism when installing it months ago? Gone in three taps. The unified dashboard loaded faster than my morning coffee brews, slamming together infrastructure stats, app performance, and container health into a single bleeding-edge view. No more tab-hopping madness. I watched real-time dependency mapping animate the carnage: a cascading failure from an overloaded API gateway to database deadlocks. The app didn't just show symptoms - it exposed the disease's DNA. My pulse slowed from jackhammer to metronome rhythm as I drilled into thread dumps right there on my cracked phone screen.
Pure witchcraft happened when I tapped the "Code Diagnostics" tab. Not vague "high latency" alerts, but method-level execution traces highlighting our checkout service hemorrhaging on a poorly written JDBC connection loop. Stack traces unfurled like criminal evidence - line 284 choking threads, connection pools exhausted, the exact Java package murdering performance. I could practically smell the burning CPU cycles. Within minutes, I hot-patched the service through the app's remote terminal while simultaneously throttling user traffic via cloud controls. All from my phone, barefoot on cold tiles.
Let me rage about the notification system though. When critical alerts hit, the damn vibration pattern feels like a taser set to "cardiac arrest." I've launched my phone across bedsheets twice. And don't get me started on the dashboard customization - configuring widget layouts requires the patience of a Buddhist monk sculpting sand mandalas. But these become trivial when you're watching error rates plummet from 42% to zero in real-time, validation emails flooding in as payments process. That visceral relief? Better than any whiskey.
Three hours later, crisis averted, I finally noticed dawn cracking through the blinds. The app's topology map glowed on my nightstand - all green nodes pulsating like a healthy heartbeat. No post-mortem scavenger hunt for logs across 12 tools. No executive apologies. Just raw cross-stack visibility that transformed panic into precision. I slept holding my phone like a talisman, knowing the next disaster wouldn't find me blind.
Keywords:ManageEngine Applications Manager,news,real-time diagnostics,incident response,DevOps mobility








