My 2 AM Server Panic Savior
My 2 AM Server Panic Savior
That bone-chilling vibration ripped me from sleep at 1:47 AM - the kind of alert that floods your mouth with copper and makes your thumbs go numb. Our payment gateway had flatlined during peak overseas transactions, and I was stranded in a pitch-black hotel room with nothing but my phone's cruel glare. I fumbled for my glasses, knocking over a water bottle in the dark, as panic seized my throat. This wasn't just another outage; it was career suicide unfolding in real-time.
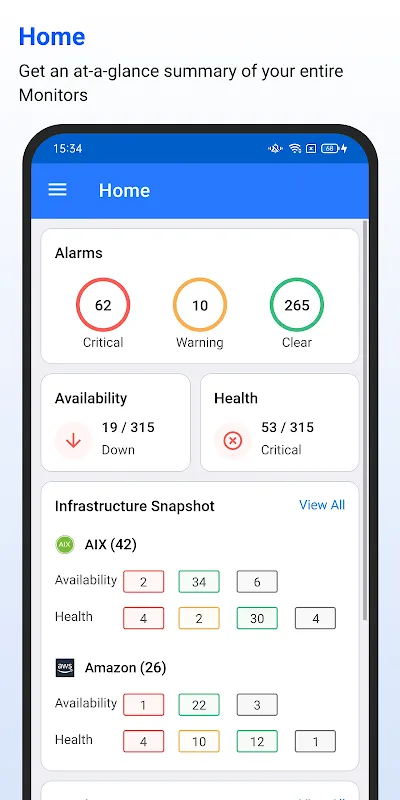
Then I remembered the crimson icon I'd reluctantly installed weeks prior. My trembling fingers stabbed at Applications Manager, expecting another useless dashboard. Instead, a live autopsy of our infrastructure bloomed on screen: Cassandra nodes hemorrhaging memory, Kubernetes pods collapsing like dominoes, all overlaid with transaction flow maps glowing like nervous systems. The magic wasn't just visualization - it was how the app threaded distributed tracing IDs through container boundaries, spotlighting exactly where our new authentication microservice was strangling database connections with poorly recycled threads.
What happened next felt supernatural. Pinching the heatmap, I drilled into the offending Java method - not just logs, but actual code-level metrics showing garbage collector thrashing. The app's secret sauce? Bytecode instrumentation that attaches lightweight probes during deployment, feeding execution traces directly to my phone. I watched stack traces unfold like tragic poetry: "HttpServlet.doPost() → AuthService.validate() → PostgresConnectionPool.get() → DEADLOCK." All while room service knocked, completely oblivious to my digital triage.
Here's where I fell in love: that tiny "Rollback" button shimmering beside the deployment analysis. One tap initiated version reversal across three cloud regions while simultaneously killing orphaned processes - orchestration that normally required three different SSH sessions. As green status lights flickered back to life, I actually laughed aloud, startling the minibar. The relief was physical, like shedding a lead vest.
But let me rage about the mobile UX sins. Navigating dependency maps feels like performing brain surgery with oven mitts - crucial pod relationships hide behind clumsy swipe gestures. And whoever designed the incident chat feature deserves eternal password resets; trying to type "AWS East-1 stabilizing" while adrenaline shakes your hands is torture. Yet these flaws almost deepen my trust, like a battle-scarred medic whose rough hands still save lives.
Now when midnight sirens blare, I reach for my phone before my pants. Last Tuesday, I averted another disaster from a beach cabana, salt spray on the screen as I throttled API queues. That's the real witchcraft - transforming panic into power through six inches of glass. My team thinks I've developed spooky intuition. Little do they know my secret weapon fits in my back pocket, humming with the quiet fury of a thousand monitoring agents.
Keywords:ManageEngine Applications Manager,news,server monitoring,DevOps emergency,mobile incident response









