When On-Calls Actually Work
When On-Calls Actually Work
The vibration started as a gentle hum against my thigh during dinner, then escalated into a violent seizure across the wooden table. My fork clattered against the plate as I fumbled for the device, the screen already blazing with that particular shade of red that means "everything is burning." Five simultaneous alerts from different systems, all screaming about database latency spikes during our highest traffic hour. My stomach did that familiar free-fall sensation, the one that usually precedes hours of frantic Slack messages and confused video calls where everyone talks over each other.
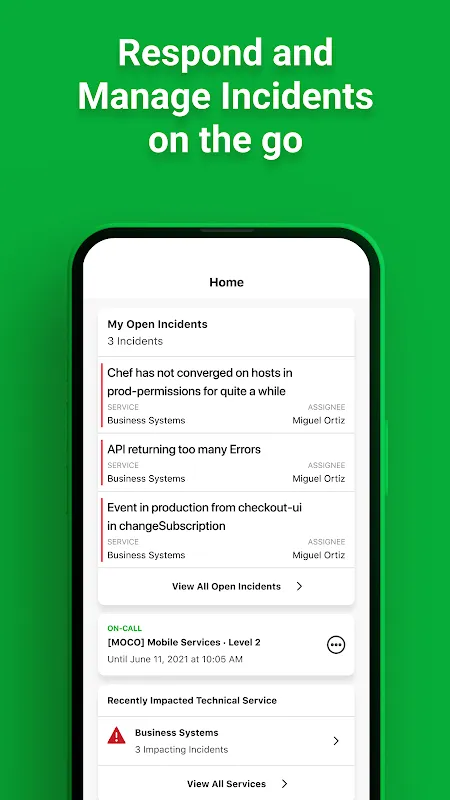
But this time was different. This time I had the response platform open before my heart rate could spike. One glance showed me the incident timeline already being populated - who was engaged, what steps were being taken, which services were affected. The chaos wasn't eliminated, but it was contained, organized, and presented to me like a battlefield map instead of a screaming mob.
The Architecture of Calm
What makes this tool different isn't the notifications - God knows we get enough of those from a dozen other systems. It's the way it structures chaos into actionable intelligence. The moment an alert triggers, the system begins its silent work: checking dependencies, correlating related events, assessing impact severity based on historical data. It's running probability algorithms in the background while I'm still rubbing sleep from my eyes.
I remember one particular night when the mobile API started throwing 500 errors. Instead of the usual panic, I watched the incident dashboard automatically group related errors, identify the deployment that likely caused it, and even suggest the on-call engineer who'd last touched that code. The system wasn't just alerting me - it was diagnosing. It had learned from thousands of previous incidents, building its own institutional memory that outlasts any single engineer's tenure.
The Human-Machine Handoff
The real magic happens in the handoff between systems. When I acknowledge an alert, the platform doesn't just mark me as "working on it" - it activates a whole suite of context gathering tools. It pulls recent deployment logs, checks monitoring graphs, and even prepares the conference bridge before I've finished typing my first response. The technical depth here is staggering when you think about the API integrations working silently in the background, querying multiple systems and presenting unified information.
There's something profoundly satisfying about watching automation handle the tedious parts of incident response. The tool automatically escalates if I don't respond within configured timeframes, but it does so intelligently - checking my calendar to see if I'm in a meeting, verifying I'm not already on another incident, even checking time zones before waking someone up. This isn't just dumb automation; it's thoughtful workflow design based on years of understanding how actual engineers work during actual emergencies.
When It Actually Frustrates
Don't get me wrong - it's not perfect. There are moments when the system's rigidity shows through. Like when it insisted on escalating to a manager because I was three minutes late responding, despite the fact that I was already typing my analysis into the incident thread. Or when the mobile app occasionally decides that notifications are optional suggestions rather than urgent demands. These moments of failure are somehow more frustrating because the tool usually works so well - you develop expectations, and when it stumbles, the disappointment feels personal.
The reporting features sometimes feel like they were designed by someone who's never actually had to explain to executives why things broke. The data is all there, but extracting meaningful insights requires more clicking and filtering than it should. I've spent hours trying to generate simple charts showing our mean time to resolution improvements, only to end up exporting raw data to spreadsheet software.
The Transformation Moment
I'll never forget the incident that changed everything for me. We had a cascading failure across multiple availability zones - the kind of event that traditionally meant all-hands-on-deck and at least eight hours of outage. But because the operational command center automatically coordinated our response, grouping related incidents and maintaining a clear timeline of actions, we contained it in forty-seven minutes.
I could actually watch the resolution unfold through the incident timeline. As engineers joined the call, their expertise was automatically documented. Actions were tracked, decisions were recorded, and when we finally identified the root cause, everything was preserved not just for post-mortem, but for training future team members. The platform didn't just help us fix things faster; it helped us learn from the failure more effectively.
The New Normal
Now when the alerts scream, I don't feel that same gut-clench of dread. There's still urgency, still pressure, but it's focused pressure. The tool has become my external brain during crises - handling the administrative overhead while I focus on technical problem solving. It remembers which runbooks to consult, which metrics to watch, and which experts to involve.
The true test came when I was on vacation in a region with spotty connectivity. When a major incident occurred, I watched from my phone as the system automatically coordinated the entire response without me. The right people were engaged, the right information was shared, and the resolution progressed while I was literally hiking up a mountain. That's when I realized this wasn't just another tool - it was an extension of our team's capabilities, working even when individuals couldn't.
There's something almost spiritual about watching technology handle technological failure so elegantly. The very systems that create complexity are now helping us manage it. The panic still comes sometimes - we're only human after all - but now we panic with purpose, with coordination, with the confidence that comes from having a truly intelligent partner in the chaos.
Keywords:PagerDuty,news,incident management,on-call response,system reliability









